Часто приходится встречать на форумах, посвященных системам хранения от IBM, жалобы пользователей, столкнувшихся с проблемой: «вставляю диск в систему, а она его не видит. что делать??!!». На вопрос «откуда взяли диски», обычно, следует ответ «на ebay купили...». Оно и понятно — стандартная гарантия IBM на популярные модели DS4800, DS4700 в большинстве своем, давно закончилась, сервисную поддержку далеко не все продлевают, вот и выкручиваются люди, как могут.
Итак. Купили диск (на ebay), вставили в систему, но диск не идентифицируется. Или проще — вытащили из одной своей системы заведомо исправный диск, вставили в другую... а диск не распознается. Кто виноват и что делать?
Для начала, немножко ликбеза.
Обычно, когда в систему вставляется новый, чистый диск, IBM’овские СХД инициализируют его, записывая в начало диска служебную область размером 512 Мб, которая называется DACstore. Там хранится различная информация о конфигурации системы хранения: конфигурация логических дисков, MEL логи, информация о подключенных хостах и т. п. Подробнее о DACstore можно почитать тут. Если диск ранее использовался в другой системе DS System Storage, то существующий DACstore будет перезаписан. И вот тут есть ньюанс. Начиная с версии микрокода 7.10, формат DACstore поменялся. Поэтому, если на системе более старая версия прошивки версии 7.xx и любая версия прошивки 6.хх (даже та, которая вышла позже 7.10), СХД просто не сможет инициализировать диск. Это и есть ситуация «не видит диск». Такие б/у диски, хоть и с фирменной лейбой IBM, но не очищеные должным образом предыдущими владельцами — не редкость даже на складах системных интеграторов. Что уж говорить про диски «с ebay».
«Лечение» в данной ситуации следующее:
- Подключаемся к системе хранения нуль-модемным кабелем
- Запускаем эмулятор терминала.
- Посылаем Ctrl+Break. Следуем инструкциям на экране — либо предложат согласовать baud rate (нажимаем пробел), либо нажать <S> для входа в Service Mode, в этом случае жмем ESC и получаем приглашение на ввод пароля. Пароль для микрокода версии 6.хх: infiniti
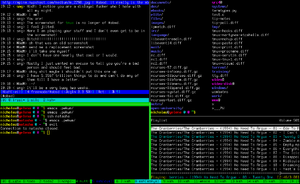
- Проверяем, что диск вообще распознался контроллером, вводим следующую команду:
-> luall
.......Logical Unit........: :Channels.:Que ............IOs...........
Devnum Location Role :ORP : 0 1 2 3 :Dep Qd Open Completed Errs
---------- -------- ------ :--- : - - - - :--- --- ----- ---------- -----
00000010 t0 Encl :++ : A B : 1 0 0 148 6
00100001 t0,s1 FCdr :+++ : * + : 16 0 0 178 2
00100002 t0,s2 FCdr :+++ : + * : 16 0 0 176 2
00100003 t0,s3 FCdr :+++ : * + : 16 0 0 177 2
00100004 t0,s4 FCdr :+++ : + * : 16 0 0 179 2
00100005 t0,s5 FCdr :+++ : * + : 16 0 0 177 2
00100006 t0,s6 FCdr :+++ : + * : 16 0 0 298 5
00100007 t0,s7 FCdr :+++ : * + : 16 0 0 470 4
00100008 t0,s8 FCdr :+++ : + * : 16 0 0 473 3
00100009 t0,s9 FCdr :+++ : * + : 16 0 0 25 1
0010000a t0,s10 FCdr :+++ : + * : 16 0 0 25 1
0010000b t0,s11 FCdr :+++ : * + : 16 0 0 25 1
0010000c t0,s12 FCdr :+++ : + * : 16 0 0 25 1
0010000d t0,s13 FCdr :+++ : * + : 16 0 0 25 1
0010000e t0,s14 FCdr :+++ : + * : 16 0 0 25 1
0010000f t0,s15 FCdr :+++ : * + : 16 0 0 25 1
00200000 t0,s16 FCdr :+++ : + * : 16 0 0 571 7
00e00011 c,this Bm :++ : + * + + : 32 0 0 0 0
00f00011 c,alt Am :++ : + * + + : 32 0 0 3532 1
Подробно объяснять вывод данной команды не буду, обратите внимания лишь на вторую колонку: это номер корзины расширения (ID на LED индикаторе на ESM, сзади полки)+номер диска. К примеру t0,s16 — 16-й диск на полке с ID 0. Очистка dacStore выполняется командой isp cfgWipe1,0x<DEVNUM> для версии микрокода 6.хх, в нашем случае:
isp cfgWipe1,0x00200000
После этого диск вытаскивается и через 30 секунд вставляется обратно.
Если вам нужно очистить DACstore на системе хранения с микрокодом 7.хх (например перед продажей на ebay ;) ), вам нужно проделать похожие операции, однако обратите внимание, что эта версия при подключении через консольный порт просит не только пароль, а и логин. Стандартные комбинации:
Команда для очистки для версии 7.хх
isp dsmWipe 0xdevnum, 0
Обратите внимание — если последним параметром указать 1, то DACstore будет перезаписан сразу после очистки. В нашем случае — мы указываем 0, поэтому DACstore будет записан только после извлечения и повторной вставки диска в СХД (ну или при выполнении процедуры SOD, но это уже совсем другая история).