
Ускорение домашнего ESXi 6.5 с помощью SSD кэширования
В данной статье хочу рассказать о том, как немного повысить производительность хоста ESXi с помощью SSD кэширования. На работе и дома я использую продукты от компании VMware, домашняя лаборатория построена на базе Free ESXi 6.5. На хосте запущены виртуальные машины как для домашней инфраструктуры, так и для тестирования некоторых рабочих проектов (как-то мне пришлось запустить на нем инфраструктуру VDI). Постепенно приложения толстых ВМ начали упираться в производительность дисковой системы, а на SDD все не помещалось. В качестве решения был выбран lvmcache. Логическая схема выглядит так:
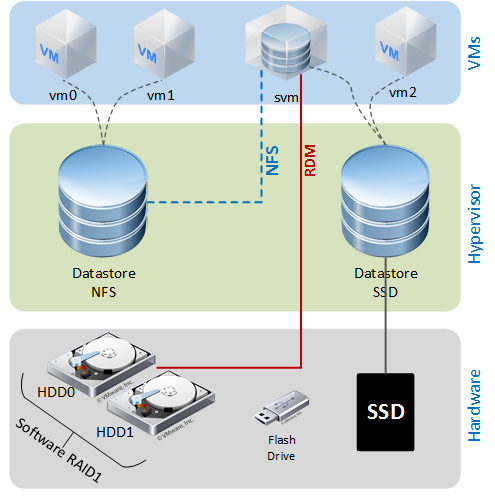
Основой всей схемы является ВМ svm на базе CentOS 7. Ей презентованы HDD диски средствами RDM и небольшой диск VMDK с датастора SSD. Кэширование и зеркалирование данных реализуются программными средствами — mdadm и lvmcache. Дисковое пространство ВМ монтируется к хосту как NFS датастор. Часть датастора SSD отведена ВМ, которым требуется производительная дисковая подсистема.
Вычислительный узел собран на десктопном железе:
MB: Gygabyte GA-Z68MX-UD2H-B3 (rev. 1.0)
HDD: 2 x Seagate Barracuda 750Gb, 7200 rpm
SSH: OCZ Vertex 3 240Gb
На материнской плате имеется 2 RAID контроллера:
— Intel Z68 SATA Controller
— Marvell 88SE9172 SATA Controller
Завести 88SE9172 в ESXi у меня не получилось (There is a bug in the firmware of some Marvell adapters (at least 88SE91xx)), решил оставить оба контроллера в режиме ACHI.
RDM
Технология RDM (Raw Device Mapping) позволяет виртуальной машине обращаться напрямую к физическому накопителю. Связь обеспечивается через специальные файлы «mapping file» на отдельном томе VMFS. RDM использует два режима совместимости:
— Виртуальный режим — работает так же, как и в случае с файлом виртуального диска, позволяет использовать преимущества виртуального диска в VMFS (механизм блокировки файлов, мгновенные снэпшоты);
— Физический режим — предоставляет прямой доступ к устройству для приложений, которые требуют более низкого уровня управления.
В виртуальном режиме на физическое устройство отправляются операции чтения\записи. RDM устройство представлено в гостевой ОС как файл виртуального диска, аппаратные характеристики скрыты.
В физическом режиме на устройство передаются практически все команды SCSI, в гостевой ОС устройство представлено как реальное.
Подключив дисковые накопители к ВМ средствами RDM, можно избавиться от прослойки VMFS, а в физическом режиме совместимости их состояние можно будет мониторить в ВМ (с помощью технологии S.M.A.R.T.). К тому же, если что-то случится с хостом, то получить доступ к ВМ можно, примонтировав HDD к рабочей системе.
lvmcache
lvmcache обеспечивает прозрачное кэширование данных медленных устройств HDD на быстрых устройствах SSD. LVM cache размещает наиболее часто используемые блоки на быстром устройстве. Включение и выключение кэширования можно производить, не прерывая работы.
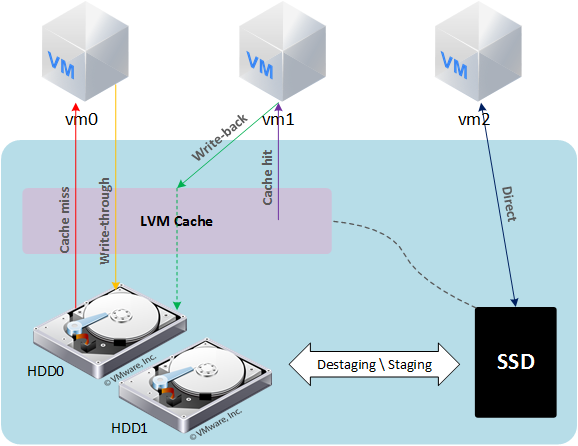
При попытке чтения данных выясняется, имеются ли эти данные в кэше. Если требуемых данных там нет, то чтение происходит с HDD, и попутно данные записываются в кэш (cache miss). Дальнейшее чтение данных будет происходить из кэша (cache hit).
Запись
— Режим write-through — когда происходит операция записи, данные записываются и в кэш, и на HDD диск, более безопасный вариант, вероятность потери данных при аварии мала;
— Режим write-back — когда происходит операция записи, данные записываются сначала в кэш, после чего сбрасываются на диск, имеется вероятность потери данных при аварии. (Более быстрый вариант, т. к. сигнал о завершении операции записи передается управляющей ОС после получения данных кэшем).
Так выглядит сброс данных из кэша (write-back) на диски:
Настройка системы
На хосте создается SSD датастор. Я выбрал такую схему использования доступного пространства:
220Gb — DATASTORE_SSD
149Gb — Отведено для особых ВМ
61Gb — Том для кэша и метаданных
10Gb — Host Swap CacheВиртуальная сеть выглядит следующим образом:
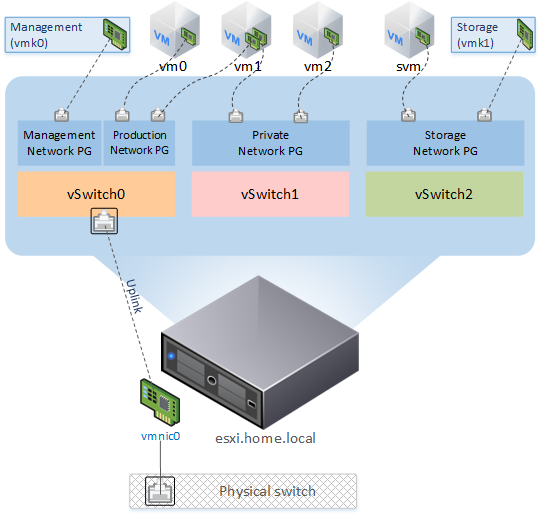
Создан новый vSwitch:
Networking → Virtual Switches → Add standart virtual switch — указываем желаемое имя виртуального свитча (svm_vSwitch, в названиях я использую префикс svm_), остальное оставляем как есть.К нему через порт группу подключается VMkernel NIC:
Networking → VMkernel NICs → Add VMkernel NIC
— Port group — New Port group
— New port group — Имя порт группы — svm_PG
— Virtual switch — svm_vSwitch
— IPv4 settings — Configuration — Static — указываем IP и маску сетиСоздана порт группа, к которой будет подключена ВМ svm:
Networking → Port Groups → Add port group — указываем имя (svm_Network) и свитч svm_vSwitchПодготовка дисков
Необходимо зайти на хост по ssh и выполнить следующие команды:
Отобразить пути всех подключенных дисков: # ls -lh /vmfs/devices/disks/ lrwxrwxrwx 1 root root 72 Feb 22 20:24 vml.01000000002020202020202020202020203956504257434845535433373530 -> t10.ATA_____ST3750525AS_________________________________________9*E lrwxrwxrwx 1 root root 72 Feb 22 20:24 vml.01000000002020202020202020202020203956504257434b46535433373530 -> t10.ATA_____ST3750525AS_________________________________________9*F Перейти в директорию, где будут размещаться «mapping file»: # cd /vmfs/volumes/DATASTORE_SSD/ Создаем RDM в режиме виртуальной совместимости: # vmkfstools -r /vmfs/devices/disks/vml.01000000002020202020202020202020203956504257434845535433373530 9*E.vmdk # vmkfstools -r /vmfs/devices/disks/vml.01000000002020202020202020202020203956504257434b46535433373530 9*F.vmdk
Подготовка ВМ
Теперь эти диски можно подключить (Existing hard disk) к новой ВМ. Шаблон CentOS 7, 1vCPU, 1024Gb RAM, 2 RDM disk, 61Gb ssd disk, 2 vNIC (порт группы VM Network, svm_Network) — во время установки ОС используем Device Type — LVM, RAID Level — RAID1
Настройка NFS сервера довольно проста:
# yum install nfs-utils # systemctl enable rpcbind # systemctl enable nfs-server # systemctl start rpcbind # systemctl start nfs-server # vi /etc/exports /data 10.0.0.1(rw,sync,no_root_squash,no_subtree_check) # exportfs -ar # firewall-cmdadd-service=nfspermanent # firewall-cmdadd-service=rpc-bindpermanent # firewall-cmdadd-service=mountdpermanent # firewall-cmd —reload
Подготавливаем тома кэша и метаданных для включения кэширования тома cl_svm/data:
Инициализация диска и расширение группы томов: # pvcreate /dev/sdc # vgextend cl_svm /dev/sdc Создание тома с метаданными, в «man» написано, что этот том должен быть в 1000 раз меньше тома с кэшем: # lvcreate -L 60M -n meta cl_svm /dev/sdc Создание тома с кэшем: # lvcreate -L 58,9G -n cache cl_svm /dev/sdc Создание кэш-пула из томов: # lvconverttype cache-poolcachemode writethrough —poolmetadata cl_svm/meta cl_svm/cache Связываем подготовленный кэш-пул с томом данных: # lvconverttype cachecachepool cl_svm/cache cl_svm/data Статистику можно посмотреть в выводе: # lvs -o cache_read_hits,cache_read_misses,cache_write_hits,cache_write_misses CacheReadHits CacheReadMisses CacheWriteHits CacheWriteMisses 421076 282076 800554 1043571
Уведомления о изменении состояния массива:
В конце файла /etc/mdadm.conf нужно добавить параметры, содержащие адрес, на который будут отправляться сообщения в случае проблем с массивом, и, если необходимо, указать адрес отправителя:
MAILADDR alert@domain.ru
MAILFROM svm@domain.ruЧтобы изменения вступили в силу, нужно перезапустить службу mdmonitor:
#systemctl restart mdmonitor
Почта с ВМ отправляется средствами ssmtp. Так как я использую RDM в режиме виртуальной совместимости, то проверять состояние дисков будет сам хост.
Подготовка хоста
Добавляем NFS датастор в ESXi:
Storage → Datastores → New Datastore → Mount NFS Datastore
Name: DATASTORE_NFS
NFS server: 10.0.0.2
NFS share: /dataНастройка автозапуска ВМ:
Host → Manage → System → Autostart → Edit Settings
Enabled — Yes
Start delay — 180sec
Stop delay — 120sec
Stop action — Shut down
Wait for heartbeat — NoVirtual Machines → svm → Autostart → Increase Priority
(Автозапуск не сработал, пришлось удалить ВМ из Inventory и добавить заново)
Данная политика позволит ВМ svm запуститься первой, гипервизор примонтирует NFS датастор, после этого будут включаться остальные машины. Выключение происходит в обратном порядке. Время задержки запуска ВМ подобрано по итогам краш-теста, т. к. при малом значении Start delay NFS датастор не успевал примонтироваться, и хост пытался запустить ВМ, которые еще недоступны. Также можно поиграться параметром
NFS.HeartbeatFrequency.
Более гибко автостарт ВМ можно настроить с помощью командной строки:
Посмотреть параметры автозапуска для ВМ: # vim-cmd hostsvc/autostartmanager/get_autostartseq Изменить значения автостарта для ВМ (синтаксис): # update_autostartentry VMId StartAction StartDelay StartOrder StopAction StopDelay WaitForHeartbeat Пример: # vim-cmd hostsvc/autostartmanager/update_autostartentry 3 «powerOn» «120» «1» «guestShutdown» «60» «systemDefault»
Небольшая оптимизация
Включить Jumbo Frames на хосте:
Jumbo Frames: Networking → Virtual Switches → svm_vSwitch указать MTU 9000;
Networking → Vmkernel NICs → vmk1 указать MTU 9000В Advanced Settings установить следующие значения:
NFS.HeartbeatFrequency = 12
NFS.HeartbeatTimeout = 5
NFS.HeartbeatMaxFailures = 10
Net.TcpipHeapSize = 32 (было 0)
Net.TcpipHeapMax = 512
NFS.MaxVolumes = 256
NFS.MaxQueueDepth = 64 (было 4294967295)Включить Jumbo Frames на ВМ svm:
# ifconfig ens224 mtu 9000 up # echo MTU=9000 >> /etc/sysconfig/network-scripts/ifcfg-ens224
Производительность
Производительность измерялась синтетическим тестом (для сравнения, я снял показания с кластера на работе (в ночное время)).
Используемое ПО на тестовой ВМ:
— ОС CentOS 7.3.1611 (8 vCPU, 12Gb vRAM, 100Gb vHDD)
— fio v2.2.8
Последовательность команд запуска теста: # dd if=/dev/zero of=/dev/sdb bs=2M oflag=direct # fio -readonly -name=rr -rw=randread -bs=4k -runtime=300 -iodepth=1 -filename=/dev/sdb -ioengine=libaio -direct=1 # fio -readonly -name=rr -rw=randread -bs=4k -runtime=300 -iodepth=24 -filename=/dev/sdb -ioengine=libaio -direct=1 # fio -name=rw -rw=randwrite -bs=4k -runtime=300 -iodepth=1 -filename=/dev/sdb -ioengine=libaio -direct=1 # fio -name=rw -rw=randwrite -bs=4k -runtime=300 -iodepth=24 -filename=/dev/sdb -ioengine=libaio -direct=1
Полученные результаты представлены в таблицах (* во время тестов отмечал среднюю загрузку ЦП на ВМ svm):
Тип диска | FIO depth 1 (iops) | FIO depth 24 (iops) | ||
|---|---|---|---|---|
randread | randwrite | randread | randwrite | |
HDD | 77 | 99 | 169 | 100 |
SSD | 5639 | 17039 | 40868 | 53670 |
SSD Cache | FIO depth 1 (iops) | FIO depth 24 (iops) | CPU/Ready* % | ||
|---|---|---|---|---|---|
randread | randwrite | randread | randwrite | ||
Off | 103 | 97 | 279 | 102 | 2.7/0.15 |
On | 1390 | 722 | 6474 | 576 | 15/0.1 |
Тип диска | FIO depth 1 (iops) | FIO depth 24 (iops) | ||
|---|---|---|---|---|
randread | randwrite | randread | randwrite | |
900Gb 10k (6D+2P) | 122 | 1085 | 2114 | 1107 |
4Tb 7.2k (8D+2P) | 68 | 489 | 1643 | 480 |
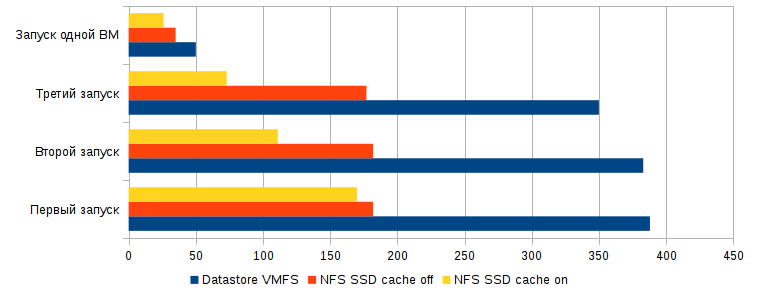
Результаты, которые можно потрогать руками, получились при одновременном запуске пяти ВМ с Windows 7 и офисным пакетом (MS Office 2013 Pro + Visio + Project) в автозагрузке. По мере нагревания кэша, ВМ грузились быстрее, при этом HDD практически не участвовал в загрузке. При каждом запуске отмечал время полной загрузки одной из пяти ВМ и полной загрузки всех ВМ.
№ | Datastore | Первый запуск | Второй запуск | Третий запуск | |||
|---|---|---|---|---|---|---|---|
Время загрузки первой ВМ | Время загрузки всех ВМ | Время загрузки первой ВМ | Время загрузки всех ВМ | Время загрузки первой ВМ | Время загрузки всех ВМ | ||
1 | HDD VMFS6 | 4мин. 8сек. | 6мин. 28сек. | 3мин. 56сек. | 6мин. 23сек. | 3мин. 40сек. | 5мин. 50сек. |
2 | NFS (SSD Cache Off) | 2мин. 20сек. | 3мин. 2сек. | 2мин. 34сек. | 3мин. 2сек. | 2мин. 34сек. | 2мин. 57сек. |
3 | NFS (SSD Cache On) | 2мин. 33сек. | 2мин. 50сек. | 1мин. 23сек. | 1мин. 51сек. | 1мин. 0сек. | 1мин. 13сек. |
Время загрузки одиночной ВМ составило:
— HDD VMFS6 - 50 секунд
— NFS с выключенным кэшем - 35 секунд
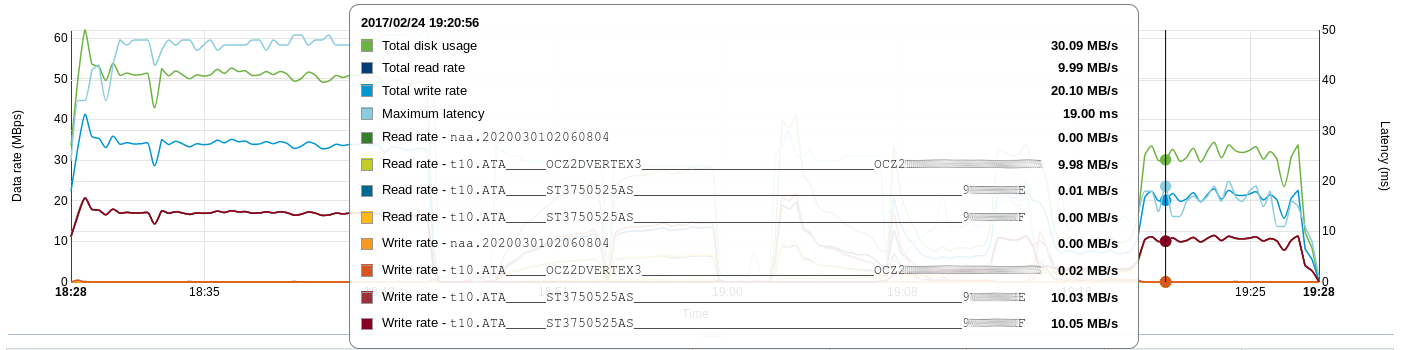
— NFS с включенным и нагретым кэшем - 26 секундВ виде графика:
Краш-тест
Отключение питания
После включения и загрузки хоста ВМ svm загрузилась с проверкой ФС (данные остались в кэше), на хосте примонтировался NFS датастор, далее загрузились остальные ВМ, проблем и потери данных не наблюдалось.
Выход из строя HDD (имитация)
Решил отключить питание SATA диска. К сожалению, горячая замена не поддерживается, необходимо аварийно выключать хост. Сразу после отключения диска появляется информация в Events.

Неприятным моментом оказалось, что при потере диска гипервизор просит для ВМ svm ответить на вопрос — «You may be able to hot remove this virtual device from the virtual machine and continue after clicking Retry. Click Cancel to terminate this session» — машина находится в состоянии фриза.
Если представить, что с диском была временная, незначительная проблема (например, причина в шлейфе), то после устранения проблемы и включения хоста все загружается в штатном режиме.
Выход из строя SSD
Наиболее неприятная ситуация — выход ssd из строя. Доступ к данным осуществляется в аварийном режиме. При замене ssd необходимо повторить процедуру настройки системы.
Обслуживание (Замена диска)
Если с диском вот-вот случится беда (по результатам S.M.A.R.T.), для того чтобы заменить его на рабочий необходимо выполнить следующую процедуру (на ВМ svm):
Посмотреть общее состояние массива: # cat /proc/mdstat или для каждого устройства: # mdadm —detail /dev/md126 /dev/md126 Пометить разделы неисправными: # mdadmmanage /dev/md127fail /dev/sda1 # mdadmmanage /dev/md126fail /dev/sda2 Удалить сбойные разделы из массива: # mdadmmanage /dev/md127remove /dev/sda1 # mdadmmanage /dev/md126remove /dev/sda2
В настройках ВМ нужно «оторвать» погибающий vHDD, затем заменить HDD на новый.
После чего подготовить RDM накопитель и добавить к ВМ svm:
Перечитать список устройств, где X — номер SCSI шины Virtual Device Node в настройках vHDD: # echo «- — -» > /sys/class/scsi_host/hostX/scan С помощью sfdisk скопировать структуру разделов: # sfdisk -d /dev/sdb | sfdisk /dev/sdc Добавить получившиеся разделы в массив, установить загрузчик и дождаться окончания синхронизации: # mdadmmanage /dev/md127add /dev/sdc1 # mdadmmanage /dev/md126add /dev/sdc2 # grub2-install /dev/sdc
Аварийный доступ к данным
Один из дисков подключается к рабочей станции, далее необходимо «собрать» RAID, отключить кэш и получить доступ к данным, примонтировав LVM том:
# mdadmassemblescan # lvremove cl_svm/cache # lvchanange -ay /dev/cl_svm/data # mount /dev/cl_svm/data /mnt/data
Также я пробовал загрузить систему непосредственно с диска, настроил сеть и на другом хосте подключил NFS датастор — ВМ доступны.
Резюме
В итоге, я использую lvmcache в режиме write-through и раздел для кэша размером 60Gb. Немного пожертвовав ресурсами CPU и RAM хоста — вместо 210Gb очень быстрого и 1.3Tb медленного дискового пространства я получил 680Gb быстрого и 158Gb очень быстрого, при этом появилась отказоустойчивость (но при неожиданном выходе из строя диска придется поучаствовать в процессе доступа к данным).